This is the second of five posts on software engineering with coding agents. The first argued that writing code became cheap and meaning did not.
A pattern I have seen often in teams adopting coding agents: they get plausible-but-wrong code from the agent and they try to fix the agent. Better prompts. More examples. Stricter style guides. Each fix works for a week, and then a new failure mode appears, and the team starts over. The work does not compound.
The agent is what it is: a probabilistic function from context to output. What is wrong is the system around it. There were no specifications to check the output against, no harness around the agent to catch the failure modes systematically, no way to turn a wrong answer into a better next iteration. Stateless functions cannot be mentored.
The lesson, and the central claim of this post: the engineering object that matters is not the agent’s output. It is the system around the agent that produces the output. That system, we call the harness. The slogan I use with my team: fix the harness, not the output.
If you are in a hurry: the post gives a small model of what the harness contains, names three disciplines for building it, distinguishes the kind of simplicity it wants from the kind formal methods already pursue, and sketches the loop that runs underneath.
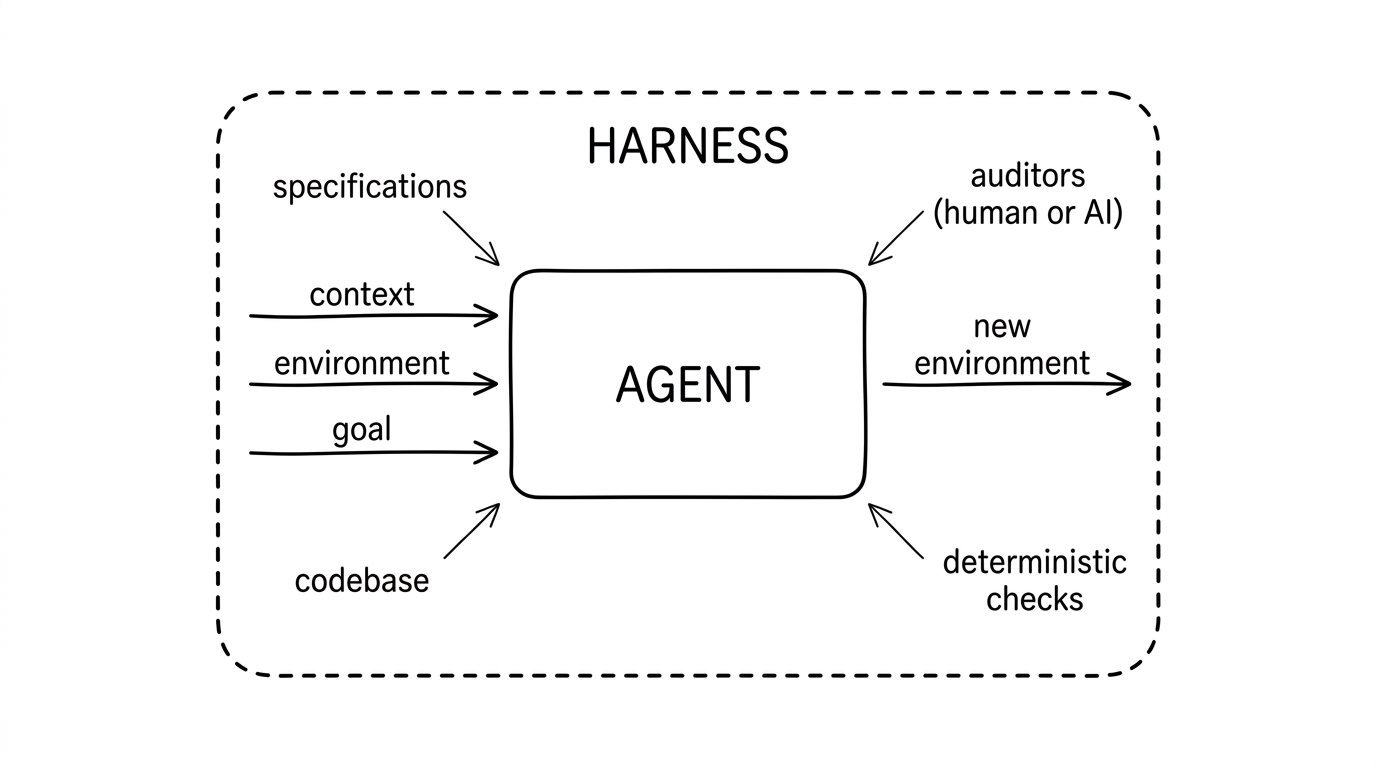
Concretely, a harness is the system that sits between the team’s intent and the agent’s output. It contains the specifications the agent must satisfy, the codebase it reads as context, the deterministic checks that run against what it produces (tests, types, properties, mutation generators, proof obligations), and the auditors, human or AI, that catch the rest. When the team’s intent shifts, the specifications shift. When a new failure mode appears, the checks expand. The harness accumulates everything the team has learned about what should pass and what should not.
Why the harness is worth fixing and the output is not
Three observations about coding agents make the harness-versus-output distinction load-bearing.
First, no model is permanent. The investment you make in a particular agent’s quirks evaporates with the next release; the investment you make in the system around it survives. The harness should be as insensitive as possible to which model is running inside it: today’s Claude or tomorrow’s, frontier or smaller, this provider or that one.
Second, the agent’s output is wrong with positive probability, by design. A 2025 USENIX Security study analysed 576,000 LLM-generated code samples across sixteen models and found that between 5% and 22% of imported packages do not exist. The model is confident, the code parses, and the package was never published. This is a property of the kind of system we are working with, not a defect of any one model. When agents are wrong they are not noisily wrong; they are confidently wrong. Two kinds of engineers, then: those who curse the model forever, and those who treat the confidence as a feature, charming once a harness is in place.
Third, the confidence has a structural workaround: iteration. If a single call succeeds with probability p, and the calls are roughly independent, then k calls produce at least one success with probability 1 − (1 − p)k. With p = 0.3 and k = 10 that is about 97%. Real calls are not independent (same model, similar prompts, shared training biases) and p must be non-trivial to begin with, but the intuition holds: the loop’s success rate climbs faster than any single call’s. We call this pattern a Ralph loop, after Geoffrey Huntley’s popularisation. The agent does not improve. The probability that the loop, taken as a whole, produces a usable output does.
These three observations point at the same conclusion: fixing the output is fixing the wrong thing. The harness is what catches confidently-wrong outputs systematically, runs the Ralph loop until the criteria are met, and stays as the model changes.
What goes in a harness
A workable model of agentic work is itself a very simple type (functional programmers, raise an eyebrow):
Agent : Ctx × Env × Goal → Env'
The agent reads three things: a context (instructions, retrieved files, prior turns, tools available), an environment (the codebase, the knowledge base, the running infrastructure), and a goal (what we asked for). It produces one thing: a new environment. The function is probabilistic; the inputs and the output are concrete.
The asymmetry between context and environment is the point. Context exists for the duration of a single call. If anything the agent reasoned about in this call needs to survive into the next, it is the harness’s job to capture it and weave it back into the next call’s context, or commit it to the environment. Environment persists by definition: the next call sees the environment that this call produced.
Three observations follow. The context is ephemeral. The goal must be explicit; an implicit goal is no goal. And the only way to improve the agent’s future behaviour is to improve the inputs. Conversely, garbage in, garbage out: ambiguity and uncertainty in the inputs come back as wrong code in the outputs, and the agent has no way to know it was wrong. The function itself is fixed once the model is chosen.
This reorients the engineering work around three disciplines, all of which contribute to the harness from different angles.
Software engineering, unchanged. The principles that make code maintainable, testable, and meaningful still apply to the codebase the harness wraps around. They apply harder now, because the agent reads the code as input. (My working assumption, which Post 3 will support with empirical evidence: better-structured code yields better outputs from the same agent.)
Knowledge engineering, new as a first-class discipline. This is where the meaning-to-specification gap that Post 1 named gets closed: turning what the team wants into specifications a machine can check. The artifacts (properties, contracts, invariants, acceptance criteria) serve two audiences at once: agents that read them to build the right context, and humans who audit and steer them to keep the team’s intent legible over time.
Harness engineering, new. The runtime that binds the layers together. It runs the agent against the specification, runs deterministic checks against what the agent produced, and routes failures back to the right discipline. Tests, type checkers, mutation engines, property-based generators, proof obligations, even other agents acting as auditors, assembled into a loop that iterates until the criteria are met.
The slogan again, with the disciplines behind it: fix the harness, not the output. When the agent produces wrong code, do not patch the code. Patch the layer of the harness that produced it: the codebase (software engineering), the specification (knowledge engineering), or the checks (harness engineering proper). The harness will produce code again, on a different problem, tomorrow.
Two kinds of simplicity
A harness should be simple. Why? Because a complex harness becomes its own engineering problem. If the harness has hundreds of deterministic checks, thousands of lines of glue code, and several layers of meta-checking, the next failure mode looks just like one of its own bugs. The team starts debugging the harness instead of the agent. The harness should stay simple enough that when the agent gets something wrong, the team can tell whether the harness missed it on purpose, by accident, or because the harness itself is broken.
There are two senses of simple in play. Adam Chlipala has put one of them most cleanly in his Substack Structure and Guarantees, in the post Formal Verification: The Ultimate Fitness Function. He calls it “an appealing division of labor, between one partner (the LLM) that is creative and unreliable and another partner (the formal verification) that is by-the-books and doesn’t miss a single detail.” The harness is the by-the-books partner, generalised: when we widen the deterministic side beyond formal verification to include tests, types, property checks, mutation, and auditors, the same division of labor applies.
Chlipala’s framing implies a kind of simplicity-for-decidability: the verifier’s job is provably complete; the certainty is categorical. We also want a different sense, simplicity-for-auditability: a human can read the harness and tell what it does, what it checks, where its boundaries are. (The shorthand pair is mine, not Chlipala’s; what matters is that the harness wants the second sense.)
The two are complementary, not equivalent. An engineer does not actually care about the auditability of a proof; what needs to be auditable is the theorem (what was proved) and the specification (what the team wants). A proof can be ten thousand lines of Coq tactics, and that is the verifier’s problem, not the engineer’s. What matters for engineering practice is whether a human can read the specification, the harness, and the result, and tell what each one claims, catches, and lets through. That is the kind of simplicity the harness wants: parts a human can name, checks that are deterministic, feedback that closes on observable criteria. Stupidly simple, not simplistic.
The working principle, while we wait for Post 5 to defend it at length: if you cannot explain to a new engineer what your harness checks, the harness is too complex.
The loop

A small process emerges from the three disciplines.
First, resolve the ambiguity. Take the vague human demand and turn it into precise questions, then into precise answers. This is the knowledge-engineering work, and it does not start when the agent is involved; it starts when the team and the stakeholders sit down to figure out what is actually wanted, and what would count as a wrong answer. The output is a specification the harness can check.
Then hand the specification, the relevant codebase, and the goal to the agent. Run the harness against what the agent produces: deterministic checks first, then auditors, then a human if anything escapes the prior layers. If the output passes, ship it. If it fails, decide which broke: the agent (run the Ralph loop), the specification (return to the knowledge-engineering work and close the gap that let the wrong thing through), or the harness (extend the checks to catch this failure mode). Repeat. On a slower cadence, the team also asks reflexive questions about the harness itself: is it still simple and auditable, is the specification still right, are we catching unknowns-unknowns or only the failures the checks were already designed for?
That is the loop. The agent is the easiest part to swap out. The knowledge base, the specification, and the harness are the durable artifacts. None of this is easy to build. It is what is worth building.
Where do engineers stand in all of this? On top, not in the path. As Kief Morris argues, the right framing is humans on top of the work, not the bottleneck of it. Engineers set the goal, audit the specification, watch the harness, and decide when to ship.
And velocity does more than speed things up. The loop runs fast enough that many decisions that used to be one-way doors become reversible. The team can try, see, revert, and try again at a cost previously associated with rough sketches. The distribution of reversible-vs-irreversible decisions shifts in the team’s favour; more of the work becomes exploration at the same level of risk.
Posts 3 and 4 examine specific instances of this loop. Post 5 defends KISS as the operating principle that keeps the process this small.
Related talk
If you prefer audio and video, the same argument runs through my talk at TezDev: Spec-Driven Agentic Development. Video on YouTube (about twenty minutes); Reveal.js slides for the standalone reading. The talk leans more on worked examples; Post 4 will revisit them at more length.
What’s next
Post 3: Same model, different harness (forthcoming). What the recent peer-reviewed research already shows. The same agent in two different setups can be ten times more useful in one than in the other, and the literature is consistent about why.
Post 4: From informal demand to machine-checkable specification (forthcoming). Three worked examples of the workflow my team has been pushing for, from a vague human want, through formal specification, into harness engineering. TezQED, the AI-assisted Michelson formal verifier. Zaynah Dargaye’s certified model-based testing for the Tezos protocol. And my recent variant of Viennot’s certified implementation of Kaplan and Tarjan’s data structure.
Post 5: First Principles for Agentic Software Engineering (forthcoming). A summary of the main ideas pushed throughout the series, the agentic dev kit I use, and a defence of KISS (Keep It Stupidly Simple) as the operating principle for the methodologies and processes of agentic software engineering. If there is one of the five you should read, that is the one.