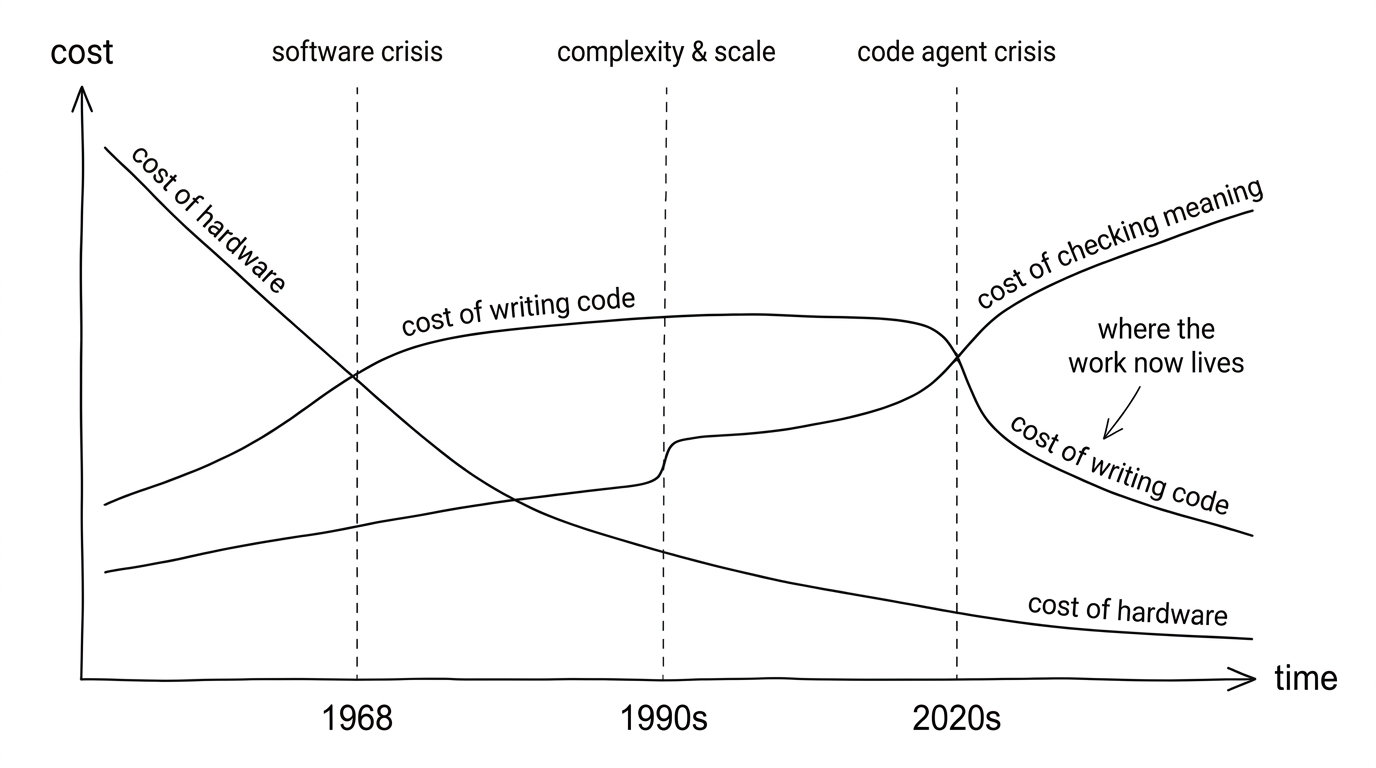
Software engineering has had two crises before. They had the same shape: something became cheap, and the work moved to whatever was still hard.
We are in the middle of a third crisis.
This is the first of five short posts on what has changed and what to do about it.
The central claim: Writing code has become cheap. Meaning has not. The gap between them, between what we want and what a machine can check, is where most of the engineering work in the agent era now lives.
If you are in a hurry, here is the rest of the post in one paragraph:
What is new in the agent era is not that machines write code, but that they write it for humans: code we are expected to read and maintain. The bottleneck shifts from writing to checking, and checking splits in two: correctness (does the code match the spec?) and meaning (was the spec right?). The engineering work now lives in the gap between them, what I call the meaning-to-specification gap.
Three eras
The history reads cleanly when you draw it.

In the first era (the 1960s and early 1970s), humans wrote code for machines. The machine’s needs were the constraint. We worked in punched cards, assembly, and hardware-specific tricks. Building hardware was expensive; building software, by comparison, was cheap. When a project failed, it was usually because the hardware did not do what we hoped. An anecdote from this era: Dijkstra invented the shortest-path algorithm in 1956 while preparing a demonstration for the ARMAC computer at the Mathematical Centre in Amsterdam. The software was incidental; the hardware was the tricky part. Hardware was the story.
The second era began with what was already called, in 1968, the software crisis, named at the NATO Conference on Software Engineering in Garmisch. Programs had grown complex enough that no one could keep them correct in their heads. Dijkstra would later put it in his Turing lecture: “the competent programmer is fully aware of the strictly limited size of his own skull.” By 1968, software engineers had already realised that the cost of building software had passed the cost of building hardware. We responded with abstraction and a more declarative style: high-level languages, ways of reasoning rigorously about programs, and design philosophies that made meaning legible to humans first, so that big systems could be kept correct.
The second crisis arrived more quietly, through the 1990s and 2000s. Programs stopped being self-contained. They had to talk to other programs across networks, depend on hundreds of libraries someone else wrote, share state across machines, and survive in environments far more chaotic than the developer’s machine. We built a new set of disciplines for it: distributed-systems thinking, dependency management, DevOps, security as a craft, and the type systems that finally made the surrounding chaos tractable. It did not get the “crisis” name that 1968 did, but the structural shape was the same: the cost of “it works on my machine” had fallen, and the cost of another thing, correctness in a wild environment, was now what mattered.
The third era, the one we are living in, is different. What is new is not that machines write code: compilers, static analyzers, and code generators have produced machine-targeted code for decades. What is new is that machines now write code for humans: code we are expected to read, review, and maintain, at the same level of abstraction we use during design. And they do everything: define the problem, propose a solution, write the tests, write the documentation. Quickly, fluently, and with no built-in guarantee that any of it is right. The rest of the series argues how to put the guarantee back.
Where the work moved
When the machine can do all that in seconds, the question is no longer how do we get the code written? The question is: how do we know we got the right thing?
This is the new crisis. The working assumption, which Post 3 supports with the recent literature: the cost of checking software has overtaken the cost of writing it. An agent will turn a vague request into a thousand lines of plausible code in a minute. Whether those lines do what we actually meant is a separate problem, and someone, usually still us, has to solve it.
The cleanest case I know: in 1999, NASA lost the Mars Climate Orbiter on approach. The flight software did exactly what its specification said. The specification assumed metric units. The propulsion team supplied imperial pounds-force. The flight code was correct in every sense a verifier could check. The meaning was wrong.
To get serious about that work, we need a distinction. There are two kinds of checking.
Correctness checking asks: did the code do what the specification said? Given a precise statement of what the code is supposed to do, does it actually do it? Tests, types, properties, formal proofs are all ways to answer that question. The community of formal methods has spent fifty years on it. The cost of their tools was long considered incompatible with most of the software industry’s constraints. This cost has dropped sharply over the last two years, thanks to AI agents. Rango (ICSE 2025), for instance, automatically proves 32% of theorems on a benchmark of real Coq projects. Laurel (OOPSLA 2025) synthesises more than 56% of the helper assertions Dafny needs to discharge real proofs.
Meaning checking asks a much less mechanical question: was the specification the right specification? It is not about algorithms. It is about people, and what they actually want. Whether a specification matches the team’s actual intent depends on what the team meant. Meaning is implicit until someone forces it into words, dynamic as the system meets reality, and ambiguous in its first formulation. A machine can read a specification; it cannot read the negotiation that produced it. This is the territory of product thinking, of building the right software.
Between the two is what I call the meaning-to-specification gap: the work of taking a fuzzy idea of what the team wants and turning it into something a machine can check. Formal methods cover the far end (precise, machine-checkable specifications). Product thinking covers the near end (vague but human-readable goals). Neither covers the middle. And the middle is where most of the engineering work in the agent era actually lives.

That is the territory the series is about. If you take one thing from this post, take this: the work has moved into the gap between meaning and specification, and naming the gap is the first move. The rest of the series argues what to build in it.
What’s next
The other four posts in this series are not yet published. Below is what they will argue, in order.
Post 2: The harness, not the output. What to do instead of more reviews. A small model of the system around the agent, the three disciplines it demands, and the slogan I use with my team: fix the harness, not the output.
Post 3: Same model, different harness (forthcoming). What the recent peer-reviewed research already shows. The same agent in two different setups can be ten times more useful in one than in the other, and the literature is consistent about why.
Post 4: From informal demand to machine-checkable specification (forthcoming). Three worked examples of the workflow my team has been pushing for, from a vague human want, through formal specification, into harness engineering. TezQED, the AI-assisted Michelson formal verifier. Zaynah Dargaye’s certified model-based testing for the Tezos protocol. And my recent variant of Viennot’s certified implementation of Kaplan and Tarjan’s data structure.
Post 5: First Principles for Agentic Software Engineering (forthcoming). A summary of the main ideas pushed throughout the series, the agentic dev kit I use, and a defence of KISS (Keep It Stupidly Simple) as the operating principle for the methodologies and processes of agentic software engineering. If there is one of the five you should read, that is the one.
I write from inside an engineering team at Nomadic Labs. The series is what we have learned about building software with agents in production: the principles that hold up, the disciplines we have actually adopted, and the recent academic work we have leaned on. To react, use the comment thread just below this post (you will need to sign in with GitHub), or reach me on X as @yurug. Feedback is warmly welcomed.